On-device AI Music Generate, 'Heartmula' 구동 도전기 (feat. Triton, OOM)

최근 로컬 환경(On-device)에서 음악을 생성할 수 있는 흥미로운 오픈소스 프로젝트, Heartmula가 공개되었습니다.
보통 생성형 AI 모델들은 거대한 서버 자원을 필요로 하는데, 내 컴퓨터에서 직접 음악을 생성할 수 있다는 점은 정말 매력적 이었습니다. 부푼 기대감을 안고 집에 있는 Mac OS (M3 Pro)환경에서 구동을 시도해 보았습니다.
결론부터 말씀드리면, 이번 시도는 OS의 장벽과 VRAM의 한계라는 두 가지 큰 산을 만나 아쉽게도 '절반의 성공?(혹은 실패)'으로 끝났습니다. (추가 - 리포지토리에 추가로 낮은 VRAM에서도 구동 가능하도록 코드가 업데이트 되었습니다. 아래 글을 쭉 읽으시면 결과물을 만나실수 있습니다.) 오늘은 그 과정을 공유해 봅니다.

1. 첫 번째 난관: Mac과 Triton의 호환성 문제
README를 꼼꼼히 읽으며 의존성 패키지들을 설치하던 중, 초반부터 치명적인 에러 로그를 마주했습니다.
Bash
ERROR: Could not find a version that satisfies the requirement triton (from versions: none)
ERROR: No matching distribution found for triton
분명 pip install triton을 실행했는데, 패키지를 찾을 수 없다는 메시지만 반복되었습니다. 원인을 파악해 보니 Triton 컴파일러의 특성 때문이었습니다.
Triton이란?
Triton은 Python 코드를 GPU가 이해할 수 있는 머신 코드(Machine Code)로 변환해 주는 컴파일러입니다. 개발자가 복잡한 CUDA C++을 직접 짜지 않고도 Python으로 GPU를 제어할 수 있게 해주는 고마운 도구죠.
문제는 Triton의 아키텍처 지원 범위였습니다.
- OS 제약: Triton은 공식적으로 Linux만을 지원합니다. (Windows는 WSL2를 통해 우회 가능하지만, Mac은 네이티브 지원이 없습니다.)
- 하드웨어 제약: Triton은 기본적으로 NVIDIA GPU(CUDA) 위에서 동작하도록 설계되었습니다.
MacBook에는 NVIDIA GPU가 탑재되어 있지 않습니다. Apple Silicon(M칩)이 아무리 좋아도, CUDA 생태계를 기반으로 작성된 라이브러리를 그대로 돌리기에는 하드웨어적(NVIDIA GPU)/소프트웨어적(CUDA, Triton) 간극이 컸습니다.
2. 전략 수정: Google Colab (Linux + NVIDIA T4)
로컬 구동은 불가능하다고 판단하고, 전략을 수정했습니다.
"Mac이 안 된다면, Linux와 NVIDIA GPU가 있는 클라우드 환경을 빌리자."
접근성이 좋은 Google Colab을 선택했습니다. Colab 무료 버전에서 제공하는 T4 GPU의 스펙은 다음과 같습니다.
- OS: Linux (Ubuntu 기반)
- VRAM: 16GB
- Disk: 약 110GB
이 정도면 Triton 설치 문제는 자연스럽게 해결되고(Linux 환경), VRAM 16GB면 웬만한 모델은 구동 가능할 것이라 예상했습니다.
3. 두 번째 난관: 16GB의 벽과 OOM
Colab 환경 세팅을 마치고, Triton을 포함한 모든 라이브러리가 정상적으로 설치되었습니다. 드디어 Heartmula를 실행시키는 순간, 터미널에 익숙하고도 슬픈 에러 메시지가 떴습니다.

설명에 나와있는대로 TORCH_CUDA_ALLOC_CONF설정을 변경해서 다시 돌려보아도 결과는 OOM이었습니다.
16GB의 VRAM으로는 Heartmula 모델을 메모리에 올리는 것조차 버거웠던 것입니다.
원인 분석
실패 후 메인테이너의 노트를 다시 확인해 보니, 하드웨어 요구 사항에 대한 힌트가 있었습니다.
- 테스트 환경: NVIDIA A100 (80GB), RTX 4090 (24GB)에서 동작 확인.
- 현재 상황: 16GB 환경인 T4에서는 모델 가중치(Weights)와 연산에 필요한 버퍼를 모두 감당하기엔 역부족이었습니다.
4. 결론 및 향후 전망
비록 이번 시도는 실패로 돌아갔지만, 가능성은 확인했습니다.
현재 Heartmula 리포지토리에는 VRAM 최적화에 대한 Pull Request가 등록되어 있습니다. 아직 완벽한 코드는 아니지만, 커뮤니티와 메인테이너가 16GB VRAM에서의 구동을 마일스톤으로 잡고 있다는 점이 고무적입니다.
On-device AI의 핵심은 '경량화'와 '최적화'입니다. 조만간 최적화 패치가 적용된다면, 다시 한번 Colab에서 나만의 음악을 만들어볼 수 있지 않을까 기대해 봅니다.
혹시 저처럼 Mac에서 삽질을 시작하려는 분이 계신다면, 바로 Linux 머신이나 Colab Pro(A100/V100) 환경을 알아보시는 것을 추천합니다. 정신 건강에 훨씬 이롭습니다.
5. 추가
lazy_load parameters가 추가되었습니다. 낮은 VRAM으로도 해당 프로젝트를 구동시킬수 있습니다! 참고
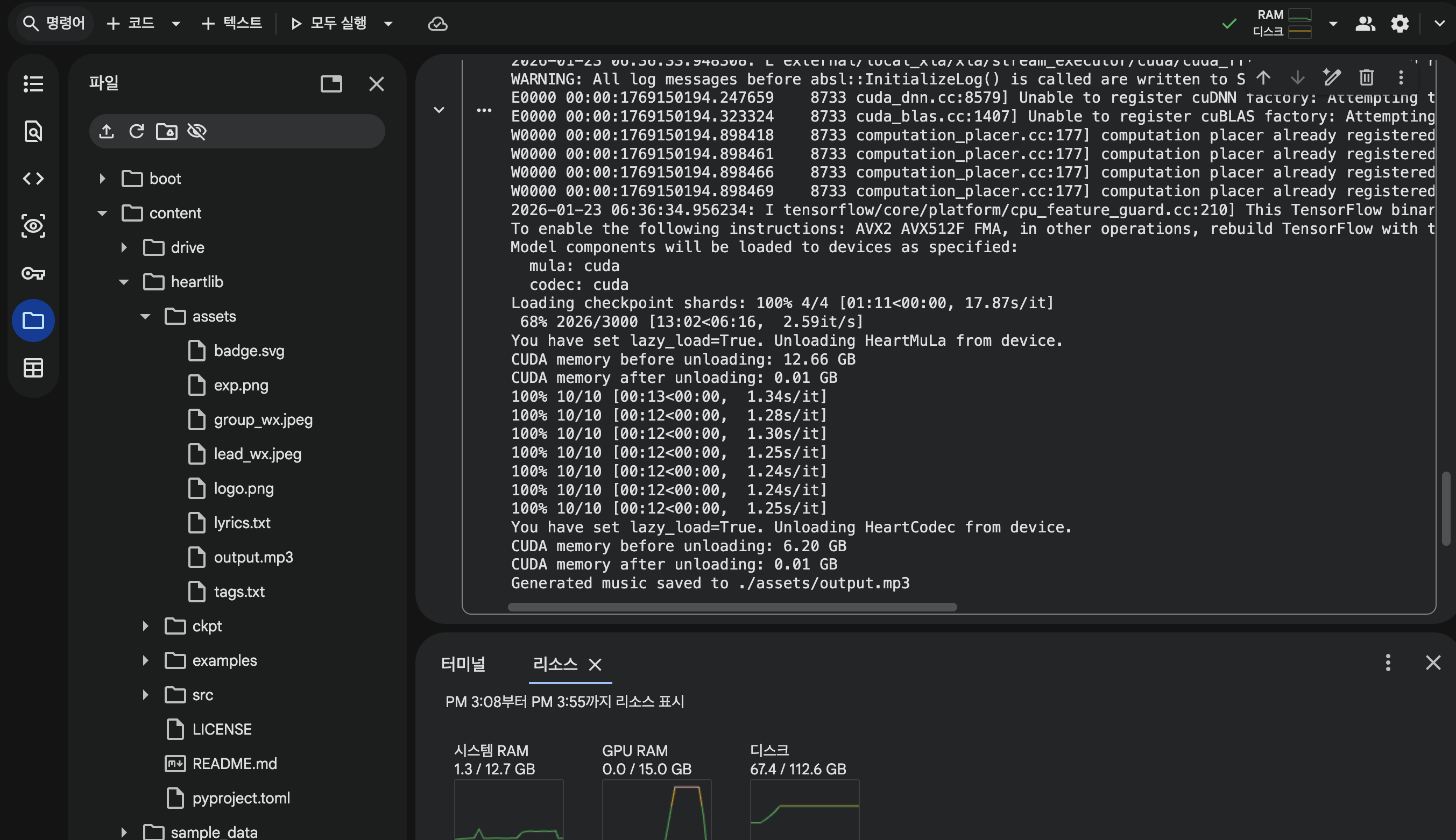
생성에 걸리는 시간은 약 20~25분 정도 걸린거 같습니다.
아래는 heartMula로 생성한 음악입니다.
Member discussion